How is the data pipeline implemented by CausalLift?
Step 0: Prepare data
Prepare the following columns in 2 pandas DataFrames, train and test (validation).
Features
a.k.a independent variables, explanatory variables, covariates
e.g. customer gender, age range, etc.
Note: Categorical variables need to be one-hot coded so propensity can be estimated using logistic regression. pandas.get_dummies can be used.
Outcome: binary (0 or 1)
a.k.a dependent variable, target variable, label
e.g. whether the customer bought a product, clicked a link, etc.
Treatment: binary (0 or 1)
a variable you can control and want to optimize for each individual (customer)
a.k.a intervention
e.g. whether an advertising campaign was executed, whether a discount was offered, etc.
Note: if you cannot find a treatment column, you may need to ask stakeholders to get the data, which might take hours to years.
[Optional] Propensity: continuous between 0 and 1
propensity (or probability) to be treated for observational datasets (not needed for A/B Testing results)
If not provided, CausalLift can estimate from the features using logistic regression.
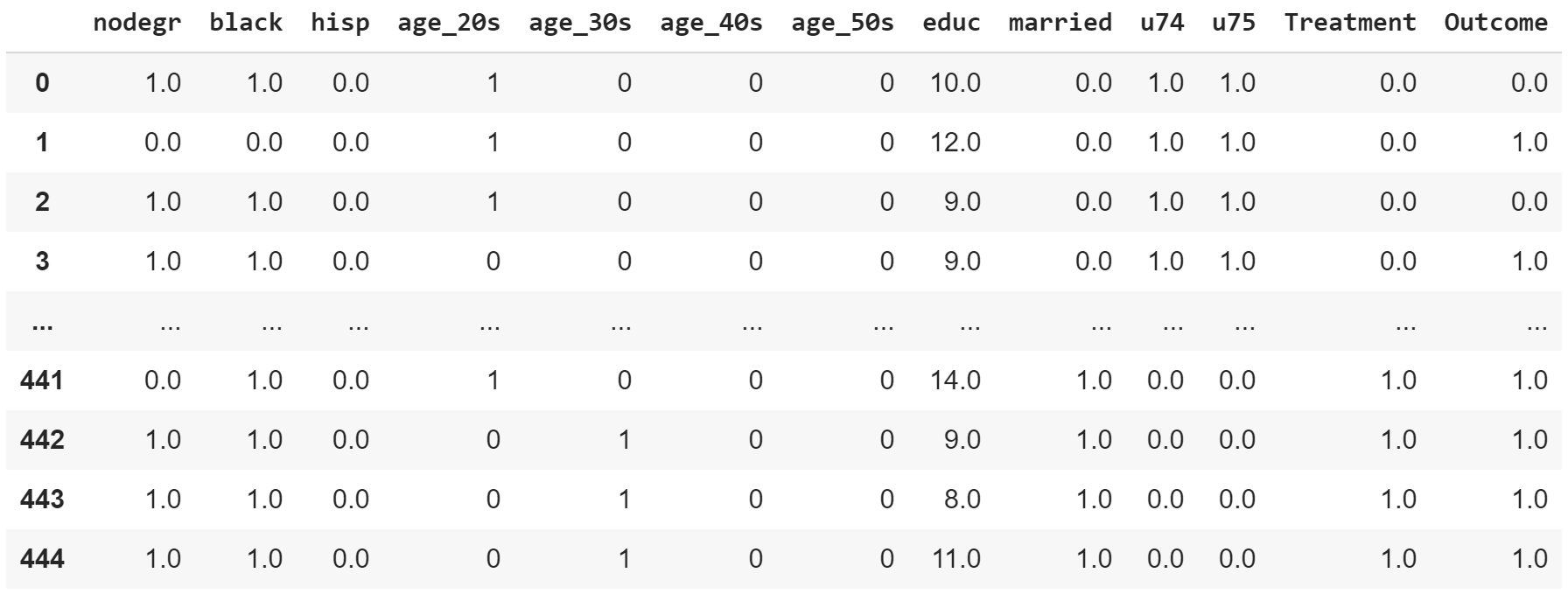
Example table data
Step 1: Prepare for Uplift modeling and optionally estimate propensity scores using a supervised classification model
If the train_df is from observational data (not A/B Test), you can set enable_ipw=True so IPW (Inverse Probability Weighting) can address the issue that treatment should have been chosen based on a different probability (propensity score) for each individual (e.g. customer, patient, etc.)
If the train_df is from A/B Test or RCT (Randomized Controlled Trial), set enble_ipw=False to skip estimating propensity score.
Step 2: Estimate CATE by 2 supervised classification models
Train 2 supervised classification models (e.g. XGBoost) for treated and untreated samples independently and compute estimated CATE (Conditional Average Treatment Effect), ITE (Individual Treatment Effect), or uplift score.
This step is the Uplift Modeling consisting of 2 sub-steps:
Training using train_df (Note:
TreatmentandOutcomeare used)Prediction of CATE for train_df and test_df (Note: Neither
TreatmentnorOutcomeis used.)
Step 3 [Optional] Estimate impact by following recommendation based on CATE
Estimate how much conversion rate will increase by selecting treatment (campaign) targets as recommended by the uplift modeling.
You can optionally evaluate the predicted CATE for train_df and test_df (Note: CATE, Treatment and Outcome are used.)
This step is optional; you can skip if you want only CATE and you do not find this evaluation step useful.