Why CausalLift was developed?
In a word, to use for real-world business.
Existing packages for Uplift Modeling assumes the dataset is from A/B Testing (a.k.a. Randomized Controlled Trial). In real-world business, however, observational datasets in which treatment (campaign) targets were not chosen randomly are more common especially in the early stage of evidence-based decision making. CausalLift supports observational datasets using a basic methodology in Causal Inference called “Inverse Probability Weighting” based on the assumption that propensity to be treated can be inferred from the available features.
There are 2 challenges of Uplift Modeling; explainability of the model and evaluation. CausalLift utilizes a basic methodology of Uplift Modeling called Two Models approach (training 2 models independently for treated and untreated samples to compute the CATE (Conditional Average Treatment Effects) or uplift scores) to address these challenges.
[Explainability of the model] Since it is relatively simple, it is less challenging to explain how it works to stakeholders in the business.
[Explainability of evaluation] To evaluate Uplift Modeling, metrics such as Qini and AUUC (Area Under the Uplift Curve) are used in research, but these metrics are difficult to explain to the stakeholders. For business, a metric that can estimate how much more profit can be earned is more practical. Since CausalLift adopted the Two-Model approach, the 2 models can be reused to simulate the outcome of following the recommendation by the Uplift Model and can estimate how much conversion rate (the proportion of people who took the desired action such as buying a product) will increase using the uplift model.
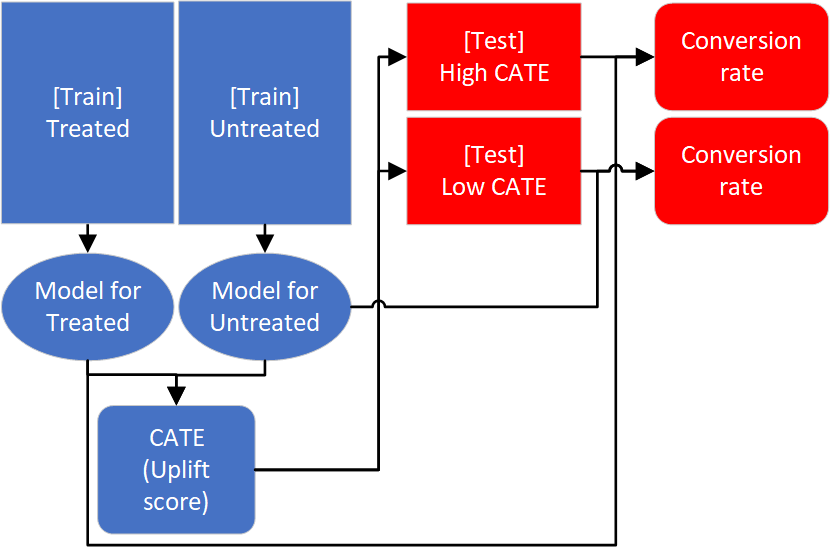
CausalLift flow diagram